Speech Recognition [ building a software product for the
recognition of the Nederlands railway stations ]
On the projects related to the speech recognition domain there are a lot of techniques and methods to be aplied so as to get to some certain results. For the current project I’ve chosen some of these methods so as to have at the final moment a project as good as possible, given the practical domain of the final software product. The goal of the project is to develop a system that can be used in order to recognize spoken words. Further discussed, the words would be the names of the National Nederlands railway stations. This will help for designing a better recognizer system by storing the probabilities of utterances for each word, station name.
The project consists in few modules. The first one is about speech signal transformation and is supposed to give the values of some reliable parameters that are as independent as possible to the changes as for instance noise, that occur in the environment at the moment of utterance of the speaker. This part is common for the two stages of the program working: the training and the recognition. The other part of the program, that is started after the part of signal transformation, is related to the way the frames that are previously computed are used to store and to test the knowledge mechanism. For that I chose the neural network way.
The signal transformation part consists in several parts that are interconnected as follows:
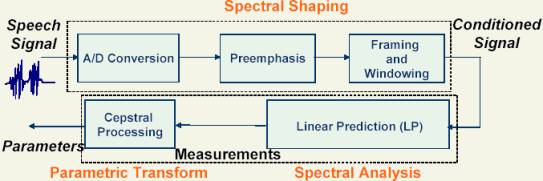
1. The A/D Conversion relates to the transformation of the signal from analog, which stands for the first way the speech wave is received, to a digital signal. For the project this process is done automatically through the sound card inside the computer. A microphone will take the signal at the first and the sound card will conver it to digital. After this stage the signal will be represented as a long raw of values that are the filtered signal.
2. The Preemphasis phase pass the digitized signal through a filter and spectrally flatten it. The filter is of the form:
![]()
For the program this will consists in applying the formula :
![]()
whre a value is set to 0.95
3. The Framing and Windowing step take the signal, the raw of values and split into small frames, of 20 milliseconds. The initial speech buffer is created following a 8 kHz microphone recording. This means that the frames will consists in packages of 8000 * 20 / 1000 = 160 samples per frame. On each sample the program apply the next steps. For the Windowing step, the frame samples are passed through the Hamming transformation. This means that for each sample of the frame ( i = 0,1, … , N-1 ) the next formula is applied:
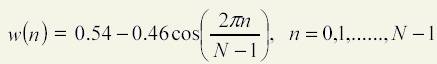
For the next frame the computing of the parameters begins at the offset the half of a frame dimension. So the next frame is computed at on offset of 10 milliseconds, or 80 samples beginning the the starting sample of the current frame.
4. The Linear Prediction step apply the Procedure of Linear Prediction Coding in order to get the parameters that is assumed to be more robust for signal representation and recognition. For the computation of the parameters, I chose the Levinson’s algorithm. It can be sketched as the following:
- compute rx[k] as :
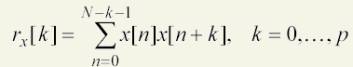
-
compute
autocorelation matrix as:
for a(1,1) :
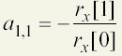
and :
![]()
for each k, k=2,3,4,..p/ p is the number of LCP parameters and is set to 12. compute:
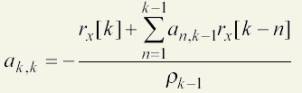
and for i = 1,2,3,..k-1 do:
![]()
and:
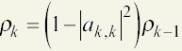
Finally
the LPC parameters will be: a( i ) = a ( i , p ), where i = 1,2,3.…p
5.
The
step is designed to compute the values of the cepstrum coefficients.These
values stands for the final transformation on the initial speech signal. For
computing these parameters the next formulas that transforms from the LPC
parameters to cepstrum are used:
![]()
and for 1 < m < p compute:
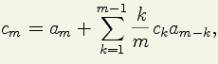
The second part, the building and
testing of the knowledge, uses a back-propagation neuronal network to store the
important informations of the speech. After passing through all the steps from
the previous section, there are p cepstral values for each frame. These will be
focused on during the next steps. Each p package of cepstral coefficients
stands for a digital representation of one certain phoneme, but in time of
course with some differences.
The network is trained so as to make
a p order vector classification for the set of phonemes.Each p set of cepstral
are in fact a phoneme. So, training with a sufficient large number of training
the neural network will have a more accurate representation of each phoneme.
The network has an input layer, a hidden and an output one. There are p input
neurons on the input layer, 50 neurons on the hidden layout and NP
neurons on the output layout. NP stands for the number of the
phoneme to be specified.
For training the network an word
example is uttered. After the previous steps there are p cepstral coefficients
for each frame of the speech sequence. The user specify the program the phoneme
representation of the uttered word. The program will identify the right phoneme
for each frame of the sequence. So, for one frame the program does a training
of the neural network by setting the p input neurons to be as the p cepstral
coefficients of the frame are. As the output vector, the program set a vector having one element set to 1 and the rest
set to 0. The index of the 1 set element is simply the index of the phoneme in
the list of phonemes on the program’s memory. By following the training for
each word from the example set at the training stage, it is assumed that the
neural network has the weights between each two neurons at a propper value so
as to make a good overall classification of any input vector at the further
moment of time.
For the testing stage, the user
speak something and the system must recognize the word. In the way the project
has been planed, based on phonemes, the recognition can be done for any word,
event for those words that have not been given at the training stage. However,
thinking of the final result of the project and its destination of the
recognition individual words that stands for railway station names, the
recognition system will be made more accurate by making a limited dictionary,
having only the words of the railway stations. In this way the accuracy of the
speech recognizer will be increased. In addition to this the program will use
the information related to the frequences of each word, being computed as the
probability for the railway station to be used as a destination. This kind of
data would be perhaps part of other module and is based on the information
provided by the Nederlands Railway Company.
The program
has so stored in its memory information for each word/station name as follows:
< station name >
the set of phonemes ~ it is a 1xN matrix , each cell is
the phoneme’s index on the list of phonemes in the memory of the program
the probability for the
station to be used as a destination by the travellers.
< station name >
At the moment of testing the user
utters a word and the system computes the cepstral coeficients of each frame.
The frames are passed through one after another, in time order.
For one
frame, the p order vector of cepstral coefficients is asigned to the neurons of
the input layer. After this, the neural network is passed through. Obviously
there will be a NP vector on the output layer. Since the
existence of different speech context, the utterance and more specifically the
phonemes will not be as at the moment of training the neural networ. This means
that it is less probable to have a sequence of one 1 value on a certain
possition and 0 on the rest on the output vector mentioned above. For this the
program computes the probabilities for all phonemes on the current frame to be
the correct uttered phoneme.
In this way the program finally has
for the sequence of frames of the uttered word, the sequence of the phonemes
with the probability vectors. Let’s assume that there are NF frames for the
uttered word. Since there are NP phonemes, the program has a matrix with NP
rows and NP columns. A column j would be the vector probability
for the frame j that indicates the probabilities for each phoneme
to be the uttered phoneme for that frame. To recognize the uttered word, the
program pass through this final matrix for each word from the dictionary and
computes the probabilities with Viterbi algorithm. For instance lets suppose
that the dictionary has two words “hoofd” and “neus”. However the project does
not deal with such words since there is about the railway station names, but
this is just an example. At the testing stage, when an utterance is received
from the microphone, the cepstral coefficients are computed and the matrix of
probabilities is done. Now, for each word (ot the two) from the dictionary the
program move to the initial frame and reads the sequence of phonetic
transcription. For each phoneme
computes the probability of that word giving the frames in this way: it checks
on the current column(frame) of the probabilities matrix the probability of the
phoneme and multiplies the previous probability value to this one.(Viterbi)
Switch to the next frame for the same word on the dictionary. Doing that for
each word the program has the probability for each word to be the uttered for
the current data/frames. The word that has the maximum probability of all the
rest is the uttered/recognized word. In the given example there are two words
that imply two probabilities: P(“hoofd”)=90% and P(“neus”)=10%.So the winning
word desemnated to be the uttered one is “hoofd”.
This is an example:
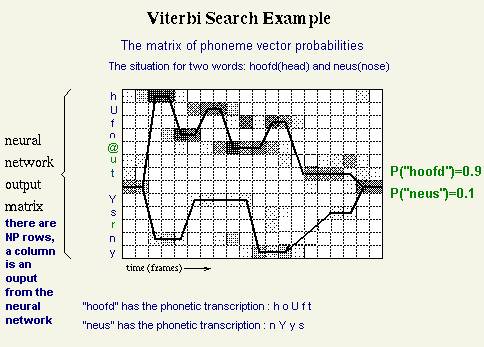
The probabilities for each word as station
names are used as descibed: after computing the probabilities the program make
a classification of the words giving their probabilities. If there is a set of
words having the probabilities with very small differencies between them, it
can be assumed that would be not an accurate situation for recognition. On this
moment the probabilities of the words from the set are used. The winning word
is that has the combined probability the maximum.
This is the idea on that the software
implementation is based for the project. There are also other possible way to
recognize uttered words with different final results. For the project the
current recognition method is assumed to give good recognition results. However
the final results will be presented as soon as they will be available.
As a requirement, the dutch utterances for the
Nederlands railway station names are needed. In addition to this the database
with the phonetic transcription is required for each word/ station name.
I’ve chosen to implement the idea described
above in Java language.
At the moment the working on the project is in progress.
Datcu Dragos
2003, January